HY-World 2.0 🔥
Core Contributor, 2026
Next-gen multi-modal world model that reconstructs, generates, and simulates 3D worlds.
Building generative AI for 3D world models.
Researcher at Tencent Hunyuan, working on the HY World model series.
Ph.D. from CityU, advised by Prof. Rynson W.H. Lau and Prof. Gerhard Hancke. During my Ph.D., I worked closely with Tengfei Wang and Ziwei Liu at Shanghai AI Lab & MMLab@NTU, and with Nanxuan Zhao at Adobe Research. My research interests span world models, 3D reconstruction, 3D asset generation, and video generation.
Core Contributor, 2026
Next-gen multi-modal world model that reconstructs, generates, and simulates 3D worlds.
Core Contributor, 2025
The first open-source world model with real-time latency, long-term memory, and interactive control.
Core Contributor, 2025
Generate immersive, editable 3D scenes from text or a single image.
*equal contribution · ^intern · †corresponding author
Technical Report, 2026
Next-gen multi-modal world model that reconstructs, generates, and simulates 3D worlds.
ECCV, 2026
Feed-forward 4D reconstruction with per-pixel 3D point trajectories under large camera motion.
ICML, 2026
Real-time interactive world model with long-term geometric memory.
ICML, 2026
Universal feed-forward 3D reconstruction — any input, any output.
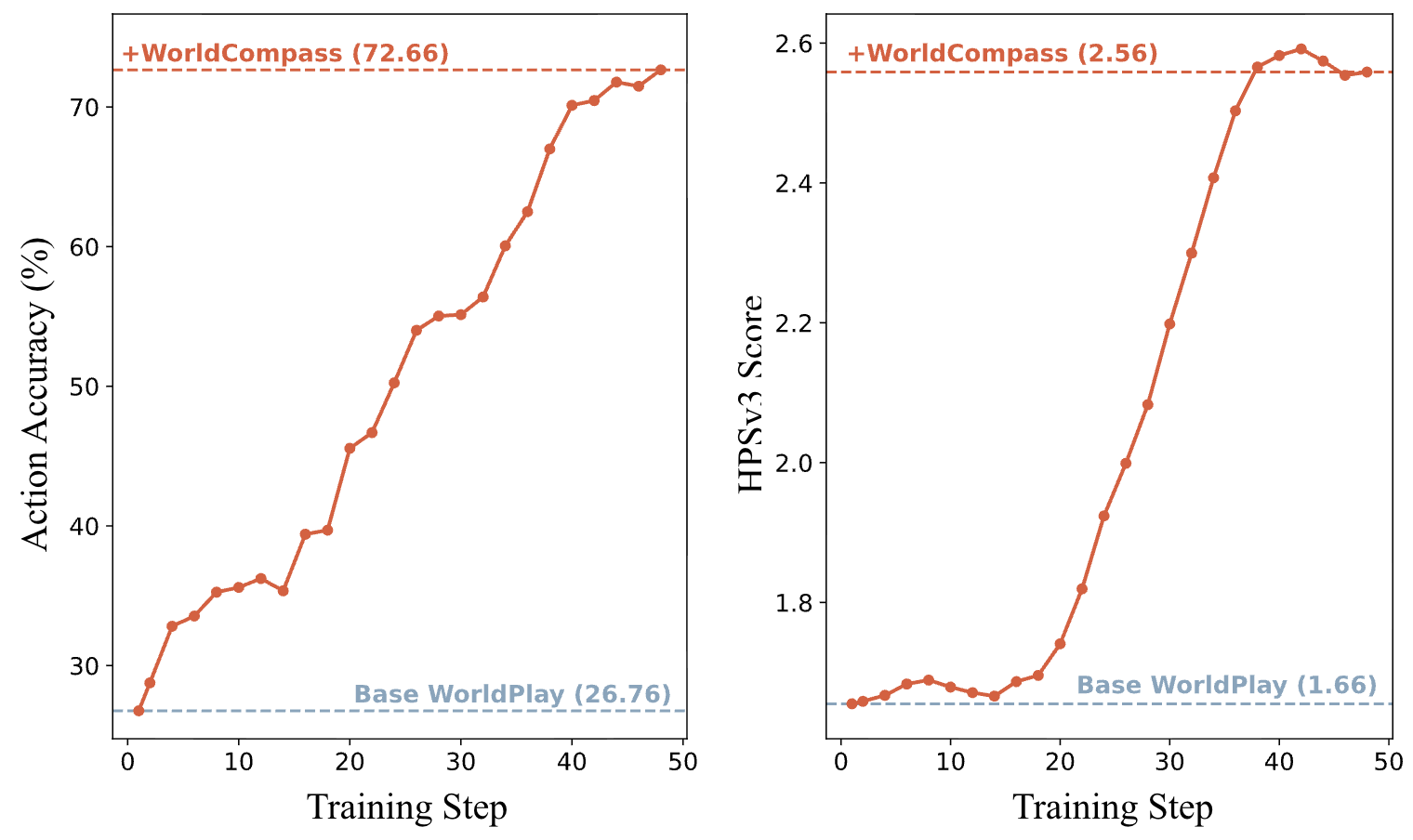
ICML, 2026
GRPO-style RL post-training for long-horizon interactive world models.
Preprint, 2025
Compositional 3D scene and object generation via sparse mixture-of-components attention.
Proc. ACM SIGGRAPH Asia, 2025
Training-free 3D asset generation with joint geometry and texture style guidance.
ACM TOG (Proc. SIGGRAPH 2025, Journal), 2025
Long-range 3D world exploration powered by RGB-D video diffusion.
Proc. ACM SIGGRAPH Asia, 2025
Precise video object manipulation via 3D proxies and diffusion rendering.
CVPR, 2025
Single-image, material-aware 3D reconstruction via G-buffer estimation.
ICLR, 2025
Retrieval-augmented 3D diffusion — generate from text, image, or existing 3D assets.
Proc. ACM SIGGRAPH, 2024
Generate theme-consistent 3D asset galleries from just a few exemplars.

AAAI, 2024
Shadow removal that restores degraded textures conditioned on recovered illumination.

ACM TOG (Proc. SIGGRAPH 2023, Journal), 2023
Language-driven photo recoloring for graphic designs.
Reviewer · SIGGRAPH, 3DV, CVPR, ECCV, ICLR, ICML, TOG, TVCG, IJCV
Teaching Assistant · Virtual Reality Technologies and Applications (CS4188 / CS5188)